O Nagios Core é uma aplicação de monitoramento de infraestrutura de rede que possui diversas funções que apoiam a gestão e visualização do status dos recursos tecnológicos em tempo real. A ferramenta é utilizada pelo NAT no monitoramento dos servidores assim como seus serviços, recursos e possíveis anomalias nestes, seja pela dashboard web e também pelos alertas automatizados.
Acesso e Conteúdo
O acesso a ferramenta é realizado pelo navegador utilizando os dados abaixo.
URL : https://54.94.202.120/nagios/
Usuário : virtueyes
Senha : 634ebffc408d
Os dados de acesso assim como o link estão disponíveis também na página principal do site do Núcleo de Apoio Técnico no Sharepoint (Intranet).
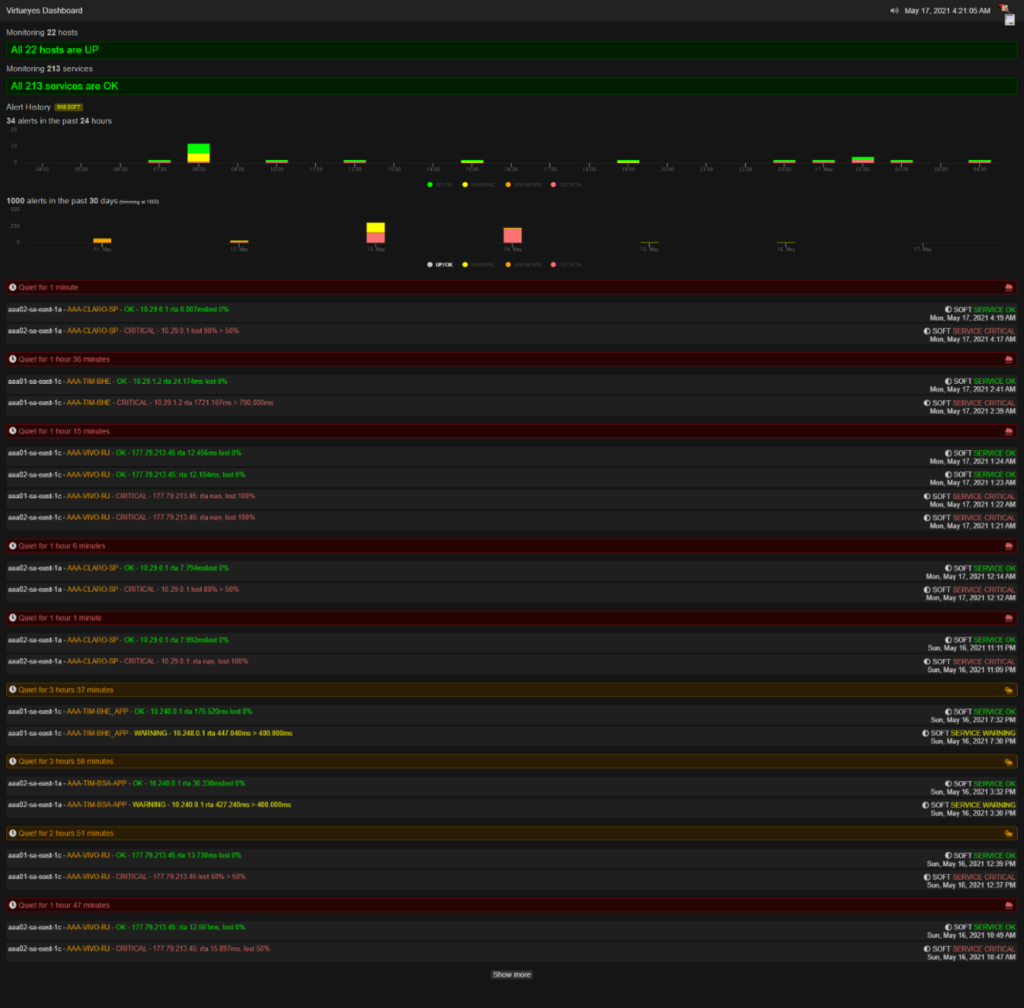
Visualizações
Atualmente trabalhamos normalmente com duas formas de visualização principais do Nagios, a primeira é a versão de grid de todos os grupos de servidores. Na qual vemos os serviços monitorados em uma visão de grelha, separados em grupos e seus servidores.
Estes têm seu estado representado por cores, sendo verde significando que o serviço está normal, amarelo significando que existe algum problema com o serviço, porém o mesmo ainda se encontra parcialmente funcional, e vermelho que representa um alerta crítico quando o serviço para totalmente de funcionar ou não pode ser monitorado.
Além da visualização anterior, também é possível visualizar o Nagios no modo TV, onde ao invés de vermos os estados de todos os serviços monitorados individualmente, temos apenas um resumo dos servidores e serviços monitorados e quantos estão funcionando normalmente, seguido de gráficos por hora que mostram a quantidade de alertas e seu tipo de acordo com a cor, como na outra visualização.
Além do gráfico temos também um histórico que mostra os últimos eventos de alertas e normalizações dos serviços monitorados. Para ter acesso a essa visualização, basta adicionar um “tv” ao final do endereço normal do Nagios no navegador.
Servidores
Servidores AAA (AAA-SA-EAST-1A e AAA-SA-EAST-1C)
Nesse grupo é apresentado os servidores AAA (1A e 1C) e suas redundâncias, túnel SP e túnel RJ. Em cada um dos servidores é apresentado os serviços junto as operadoras e alguns itens monitorados destas máquinas.
Criticidade: Alta
Servidores ACCT (ACCT)
Servidores ACCT (ACCT1,ACCT2 e ACCT4) são servidores de banco de dados do Accounting sendo que a diferença entre eles é que o ACCT4 além de guardar dados do Accounting totalizados também guarda dados da aplicação V.Eye. O ACCT1 (Golden Cop) recebe as informações que são guardadas e após transferidas para o ACCT2 e do ACCT2 as informações são transferidas para o ACCT4.
Criticidade: Alta
Servidores Linux (ACCTDB e LINUX-SERVERS)
Esse grupo temos dois servidores ACCT2 e ACCT4 sendo que referem-se puramente aos servidores linux.
Criticidade: Alta
Servidores DNS Linux (DNS)
Esse grupo abrange o servidor de DNS da nossa estrutura. Os servidores DNS (Domain Name System, ou sistema de nomes de domínios) são os responsáveis por localizar e traduzir para números IP os endereços dos sites que digitamos nos navegadores.
Criticidade: Alta
Firewalls (FW-SA-EAST-1A e FW-SA-EAST-1C)
Esses dois itens apresentados referem-se aos nossos dois firewalls.
Criticidade: Alta
Servidores ACCT (JOB-SA-EAST-1A)
Máquina específica para processos executa e monitora backups, inclusão de linhas entre outras funções.
Criticidade: Média (Problemas podem ser tratados no horário comercial)
Linux Server
Esse tópico se refere-se a própria máquina da aplicação Nagios (Localhost) então se ela estiver fora de funcionamento nenhum alerta será gerado sobre os demais hosts.
Criticidade: Alta
AAA Servers (STREAM-SA-EAST-1A e STREAM-SA-EAST-1C)
Esse grupo se refere aos consumidores dos AAAs, esse consumo alto que gera filas de eventos pendentes.
Criticidade: Alta
Linux WEB (WWW)
Esse item refere-se ao servidor da plataforma V.Eye e ao monitoramento dos seus serviços.
Criticidade: Alta
Alertas
Seguem abaixo alguns dos alertas e suas informações.
– AAA – Operadora: Serviço referente a conexão junto a operadora.
– Freeradius: Serviço de Autenticação, Autorização e Auditoria.
– CPU Load: Carga de CPU sendo utilizada
– Current Users: Usuários acessando esta máquina.
– Disk Check: Verificação de disco.
– Ping: Teste de resposta de rede.
– Total Processes: Número total de processos sendo executados.
– Uptime: Tempo que a máquina está online.
– Zombie Processes: Processos pendurados a muito tempo sem finalizar.
– CPUUSAGE: Uso de CPU.
– LOAD5MIN: Processos que estão pendurados a mais de 5 minutos.
– MEMFREE: Memória livre.
– Interface Statistc: Estatísticas da interface de rede do servidor.
– Openfiles: Número de arquivos abertos no Linux ao mesmo tempo.
– Tmp-Disk-table: Informa os arquivos aberto que não foram finalizados.
– Long-running-procs: Processos que estão há muito tempo rem execução.
– Total processes: Totaliza o número de processos sendo executados na máquina.
– Uptime: Tempo que a máquina está online.